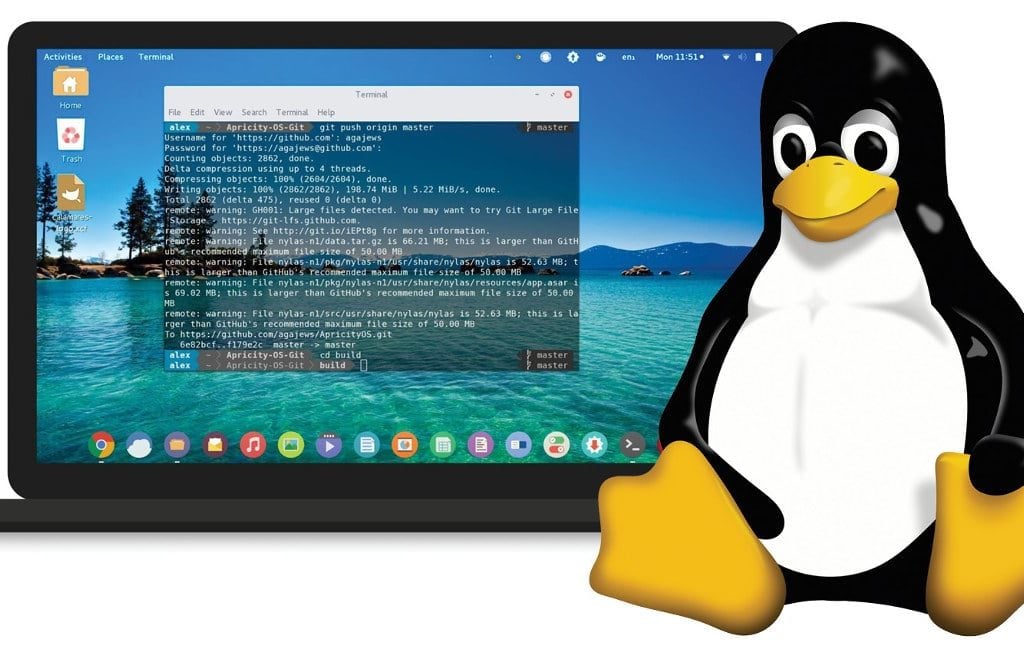
The Domain Information Groper command, or “dig” for short, collects data about Domain Nameservers and enables troubleshooting DNS problems.
It’s popular mainly because it is one of the simplest and most flexible networking commands and provides a clearer output than the host command.
You can use the dig command on Linux and Unix machines to perform DNS lookups, verify ISP internet and DNS server connectivity, check spam and blacklisting records, find host addresses, mail exchanges, nameservers, CNAMEs, and more.
In this guide, we’ll walk you through how the command works. Boot your machine, launch a terminal, and ensure you have sudo privileges, and we’re ready to go.
The Basics of the dig Command
There are three things you must know about the dig command before learning how to use it:
#1 Syntax
The syntax of the dig command looks like this:
| dig @[server] [name] [type] |
As you can see, the dig command can be coupled with three arguments.
You must put the IP address or name in [server]’s place. The argument is the name or IP of the nameserver you want to get the DNS information of. Supplying this argument is optional, and if you skip it, the command will check the /etc/resolv.conf file and use the nameservers there.
The [name] argument is where you must put the DNS of the server. Finally, the [type] argument, as you’d expect, sets the record type to retrieve. It uses the “A” record type by default, but there are others you can set.
The different types and their meanings are in the table below.
| Type |
Purpose |
| A |
IPv4 IP address |
| AAAA |
IPv6 IP address |
| CNAME |
Canonical name record (Alias) |
| MX |
Email server host names |
| NS |
Name (DNS) server names |
| PTR |
Pointer to a canonical name typically used to implement reverse DNS lookups |
| SOA |
Authoritative information about a DNS zone |
| TXT |
Text record |
Installing dig
Most Linux distros come with the dig command pre-installed, but if you aren’t sure if it’s on your machine, try running the command below on a terminal:
The command above is the version command and will return a numeric version code if the dig command is on your machine. If the command doesn’t run because your machine can’t find it, here’s how you can install it on Ubuntu and Debian:
| sudo apt-get install dnsutils |
If you’re running RedHat or CentOS, you can use this command:
| sudo yum install bind-utils |
Post installation, verify whether you can use the command with “dig -v.”
What Using the dig Command Looks Like
Let’s say you want to find the IP address of some host, for instance, www.google.com. To use the dig command, open a terminal and type:
The dig command will return a huge output with a handful of sections, of which three are the most relevant.
The first section is the questions section, where you’ll find the query type. As mentioned earlier, the query type is “A” by default.
The second section is the answer section, where you’ll find the IP address you were looking for. The stats section is the last and displays interesting statistics such as query time, server names, and more.
Examples of Using the dig Command
Though the dig command is simple, there are several different ways of using it. We’ve discussed the most useful ways of using the dig command:
#1 DNS Lookup
In the example above, we performed a basic IP lookup. In this example, we will see how you can perform a DNS lookup and also discuss the sections of the dig command’s output in detail.
Begin by running the dig command with a domain name like so:
At the beginning of the output, you will see the version of the dig command you are using. You will see the domain name you’ve supplied to the command next to this information.
In the next line, you will see the global options you have supplied.
Then comes the HEADER section, where you will see the information the command received from the server. Under this section, you will also find the flags, which refer to the answer format.
Next appears the OPT PSEUDOSECTION, which displays advanced data such as EDNS, flags, and UDP.
The QUESTION section is the penultimate section and comprises three columns. The first shows the queried domain name, the second indicates the query type, and the third specifies the record.
The final section is the ANSWER section with five columns. The first displays the queried server’s name, and the second indicates the “Time to Live,” which is the set timeframe post which a record is refreshed.
The next two columns show you the class and type of query, respectively. The last column holds the domain name’s IP address.
Though the ANSWER section is officially the final section, there is another section of information before the command’s output ends. This is referred to as the STATISTICS section.
It holds the query time, IP address, port, timestamp of when the command ran, and the DNS server’s reply size.
#2 Querying DNS Servers
The dig command determines which nameserver to query according to the local configuration. But you can specify which nameserver you want to query by mentioning it before the domain name with an “@” sign behind it.
Here’s what this would look like for our www.google.com example:
The output will indicate how many servers were found and show you all the details you need to know.
Bear in mind that you may see other domain nameservers specified in the output. These may include your ISP’s DNS server or your server hosting company’s nameserver.
#3 The ANY Option
If you want to see all the information the dig command fetches, you can use the ANY argument like so:
You will see all of Google’s DNS records and IP addresses.
Note that you can substitute ANY in the command above with other record types mentioned earlier in this post in a table. Of course, you can also not mention any record type if you’re unsure which one you should use.
#4 The “Short Answer” Option
Use the short option if you only want to see the domain name’s IP address and no other information is relevant to you. Here’s what using it looks like:
#5 The “Detailed Answer” Option
Running the dig command with the +noall and +answer options will increase the amount of information in the ANSWERS section of the output.
Here’s how you would use these options:
#6 The Trace Option
To determine the servers your query passes through before getting to its final destination, use the +trace option like so:
#7 Reverse DNS Lookup
The dig command enables you to search for a domain name with its IP address with the -x option. Here’s how you use it:
Note that you can combine this option with the other options we’ve discussed.
#8 Reading Host Names from a File in Batch Mode
Looking up multiple entries by writing dig commands for each can be tedious. But the nice thing is that the command supports batch processing.
To use this feature, begin by creating a file with all the relevant domain names. Run:
| sudo nano domain_name_list.txt |
Enter the superuser password and type the domain names in the file before saving and exiting. Now you’re ready to use the dig command with the -f option:
| dig -f domain_name_list.txt +short |
#9 Adjusting the Default Options
If you find yourself needing to use the same options repeatedly, consider altering the default results of the dig command. You can do this by modifying the ~/.digrc file with the following command:
The file will open, and you can add the options you want the command to process by default. Exit by hitting Ctrl and “x,” then run the command again to see your changes in action.
#10 Finding TTL for DNS Records
The “Time to Live” mechanism limits the lifetime of the DNS records in the DNS.
An authoritative DNS server runs this mechanism for each resource record. As you might guess, the TTL is set in seconds and used by recursively caching the DNS server. The idea is to speed up DNS name resolution in this way.
The following command determines the TTL:
| dig +nocmd +noall +answer +ttlid A www.google.com |
#11 Setting Query Transport Mode
Forcing dig to use the query transport mode is as simple as using the -4 option for IPv4 and the -6 option for IPv6.
#12 Specifying Port Number for DNS Queries
The dig command resorts to using the TCP or UDP port 53 when sending a query by default. But you can send queries on another port with the -p option. The syntax of using the option looks like this:
Conclusion
The examples illustrated in this guide should help you get the hang of using dig in no time. When you get comfortable using it, it’s a good idea to check out the official documentation for the command on the IBM website.
You will find descriptions of all the query options and flags available. Of course, you can also run “man dig” on the terminal to find the manual for the command. The help option “-h” will give you the same result.
Don’t hesitate to try using the different options and flags conjunctly – you might get some insights you didn’t expect!





 Christine Tomas is a tech expert, consultant, and aspiring writer.
She writes for different news portals and thematic blogs for tech
experts that helps her stay at the heart of programming, technology
news.
Christine Tomas is a tech expert, consultant, and aspiring writer.
She writes for different news portals and thematic blogs for tech
experts that helps her stay at the heart of programming, technology
news.











")