 Have you ever searched your name or your brand and found content that you didn’t expect to see?
Have you ever searched your name or your brand and found content that you didn’t expect to see?
Maybe a page that doesn’t represent you well or something you want to keep track of for your records?
If you’re using Linux or Unix, you’re in a great position to take control of that situation. With just a few simple tools, you can save, organize, and monitor any kind of web content with ease.
This guide walks you through how to do that, step by step, using tools built right into your system.
This isn’t just about removing content. It’s also about staying informed, being proactive, and using the strengths of Linux and Unix to help you manage your digital presence in a reliable way.
Let’s take a look at how you can start documenting web content using your system.
Why Organizing Online Content Is a Smart Move
When something important appears online—like an article that mentions you, a review of your product, or even a discussion thread—it helps to keep a copy for reference. Many platforms and services ask for details if you want them to update or review content. Having all the right information at your fingertips can make things smoother.
Good records also help with transparency. You’ll know exactly what was published and when, and you’ll have everything you need if you ever want to take action on it.
Linux and Unix systems are perfect for this kind of work because they give you flexible tools to collect and manage web content without needing extra software. Everything you need is already available or easily installable.
Start by Saving the Page with wget
The first step is to make sure you have a full copy of the page you’re interested in. This isn’t just about saving a screenshot—it’s about capturing the full experience of the page, including images, links, and layout.
You can do this with a built-in tool called wget. It’s easy to use and very reliable.
Here’s a basic command:
css
CopyEdit
wget –mirror –convert-links –adjust-extension –page-requisites –no-parent https://example.com/the-page
This command downloads the full version of the page and saves it to your computer. You can organize your saved pages by date, using a folder name like saved_pages_2025-04-10 so everything stays neat and searchable.
If you don’t have wget already, most systems let you install it quickly with a package manager like apt or yum.
Keep a Log of Your Terminal Session
If you’re working in the terminal, it’s helpful to keep a record of everything you do while gathering your content. This shows a clear trail of how you accessed the information.
The script command helps with this. It starts logging everything that happens in your terminal into a text file.
Just type:
perl
CopyEdit
script session_log_$(date +%F_%H-%M-%S).txt
Then go ahead and run your commands, visit links, or collect files. When you’re done, just type exit to stop the log. This gives you a timestamped file that shows everything you did during that session, which can be useful if you want to look back later.
Capture Screenshots with a Timestamp
Screenshots are one of the easiest ways to show what you saw on a page. In Linux or Unix, there are a couple of simple tools for this.
If you’re using a graphical environment, scrot is a great tool for quick screenshots:
nginx
CopyEdit
scrot ‘%Y-%m-%d_%H-%M-%S.png’ -e ‘mv $f ~/screenshots/’
If you have ImageMagick installed, you can use:
perl
CopyEdit
import -window root ~/screenshots/$(date +%F_%H-%M-%S).png
These tools save screenshots with the date and time in the filename, which makes it super easy to sort and find them later. You can also create a folder called screenshots in your home directory to keep things tidy.
Use Checksums to Confirm File Integrity
When you’re saving evidence or tracking content over time, it’s a good idea to keep track of your files’ integrity. A simple way to do this is by creating a hash value for each file.
Linux and Unix systems come with a tool called sha256sum that makes this easy.
Here’s how you can use it:
bash
CopyEdit
sha256sum saved_page.html > hash_log.txt
This creates a unique signature for the file. If you ever need to prove that the file hasn’t changed, you can compare the current hash with the original one. It’s a good way to maintain confidence in your saved content.
Organize Your Files in Folders
The key to staying organized is to keep everything related to one event or day in the same folder. You can create a structure like this:
bash
CopyEdit
~/web_monitoring/
2025-04-10/
saved_page.html
screenshot1.png
session_log.txt
hash_log.txt
This kind of structure makes it easy to find and access your saved pages later. You can even back these folders up to cloud storage or an external drive for safekeeping.
Set Up a Simple Monitor Script
If you want to stay on top of new mentions or changes to a particular site or keyword, you can create a simple watch script using the command line.
One popular method is to use curl to grab search results, then filter them with tools like grep.
For example:
bash
CopyEdit
curl -s “https://www.google.com/search?q=your+name” > ~/search_logs/google_$(date +%F).html
You can review the saved file manually or use commands to highlight certain keywords. You can also compare today’s results with yesterday’s using the diff command to spot new mentions. Additionally if needed you can also go for how do you delete a google search result.
To automate this, just create a cron job that runs the script every day:
nginx
CopyEdit
crontab -e
Then add a line like this:
ruby
CopyEdit
0 7 * * * /home/user/scripts/search_watch.sh
This runs the script at 7 a.m. daily and stores the results in a folder you choose. Over time, you’ll build a personal archive of search results that you can refer to anytime.
Prepare Your Submission Package
If you ever need to contact a website or a service provider about a page, it’s helpful to have everything ready in one place. That way, you can share what you’ve collected clearly and professionally.
Here’s what you might include:
- The exact URL of the page
- A brief explanation of why you’re reaching out
- A copy of the page you saved
- One or more screenshots
- A summary of what you’re requesting
Some platforms also have forms or tools you can use. For example, search engines may provide an online form for submitting requests.
If you want to contact a site directly, you can use the whois command to find the owner or hosting provider:
nginx
CopyEdit
whois example.com
This will give you useful contact information or point you toward the company that hosts the site.
Automate Your Process with Cron
Once you have everything set up, you can automate the entire workflow using cron jobs. These scheduled tasks let your system do the work while you focus on other things.
For example, you can schedule daily page saves, keyword searches, or hash checks. This makes your documentation process consistent and thorough, without any extra effort after setup.
Linux and Unix give you the tools to turn this into a fully automated system. It’s a great way to stay prepared and organized using technology you already have.
Final Thoughts
Linux and Unix users have a unique advantage when it comes to documenting web content. With simple tools like wget, script, and scrot, you can create a complete, organized snapshot of any page or event online. These tools aren’t just powerful—they’re also flexible and easy to use once you get the hang of them.















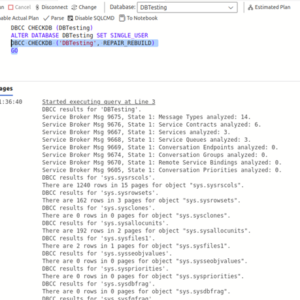 If REPAIR_REBUILD tool fails to repair the problematic MDF file then you can try the below REPAIR_ALLOW_DATA_LOSS command of DBCC CHECKDB command:
If REPAIR_REBUILD tool fails to repair the problematic MDF file then you can try the below REPAIR_ALLOW_DATA_LOSS command of DBCC CHECKDB command: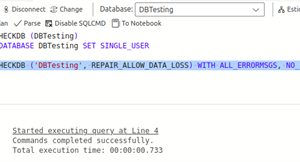 Next, change the mode of the database from SINGLE_USER to MULTI_USER by executing the below command:
Next, change the mode of the database from SINGLE_USER to MULTI_USER by executing the below command: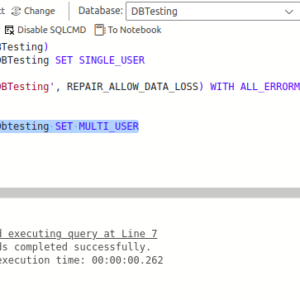 Using the above command can help you repair corrupt MDF file but it may removes majority of the data pages containing inconsistent data while repairing. Due to which, you can lose your data.
Using the above command can help you repair corrupt MDF file but it may removes majority of the data pages containing inconsistent data while repairing. Due to which, you can lose your data. After selecting an MDF file, click Repair.
After selecting an MDF file, click Repair. 





 TS file is a standard format for video and audio data transmission. TS file stands for transport stream file. This format of file is commonly used for broadcasting, video streaming, and storing media content in a structured format.
TS file is a standard format for video and audio data transmission. TS file stands for transport stream file. This format of file is commonly used for broadcasting, video streaming, and storing media content in a structured format.
 When people think of the word ‘bots’, they often think of it in negative terms. Bots, of course, are one of the biggest threats to companies in 2025, with security incidents involving bots rising by 88% last year alone. But if you’re running a business, there are two types of bots you should know about: malicious bots and beneficial bots.
When people think of the word ‘bots’, they often think of it in negative terms. Bots, of course, are one of the biggest threats to companies in 2025, with security incidents involving bots rising by 88% last year alone. But if you’re running a business, there are two types of bots you should know about: malicious bots and beneficial bots. 


 Java is everywhere in the tech community. Since its launch in 1995, with multiple versions, new features, performance improvements, and security patches, Java has evolved a lot. With these many versions, comes a new problem. Which Java version should you choose? By default, everyone thinks that the latest version is always the best.
Java is everywhere in the tech community. Since its launch in 1995, with multiple versions, new features, performance improvements, and security patches, Java has evolved a lot. With these many versions, comes a new problem. Which Java version should you choose? By default, everyone thinks that the latest version is always the best.
 When you are configuring your SSD in a Linux system, one of the most important deciding factors is selecting the correct partition style. The question boils down to GPT or MBR? Which partition style to choose? This choice is very important because this affects the compatibility, performance, and system stability of your device.
When you are configuring your SSD in a Linux system, one of the most important deciding factors is selecting the correct partition style. The question boils down to GPT or MBR? Which partition style to choose? This choice is very important because this affects the compatibility, performance, and system stability of your device.

