
All the techniques and methods used to improve the availability of a system or a service and increase the fault tolerance are called High Availability, such example of fault we can mention: hardware redundancy, clustering, replication of data at hot physically (RAID 1 and RAID 5) or in software (Snapshots, DRBD), or crisis scenarios (degraded mode, emergency plan). In a large company, it can lead to a position of responsibility at full time. You will see a picture to implement a facet of this problem in this article: an active / passive cluster that ensures the availability of an application service.
Concerning GNU / Linux, in this article two software that could manage a cluster infrastructure were tested:
- Heartbeat which has its proofs but it is limited: no cluster from more than 2 nodes, no management of resources and rules to switch from one node to another.
- Corosync and Pacemaker: It is the choice of the Red Hat distribution and which be outlined later in this article.
We had mounted a representative model composed by two virtual machines Debian Wheezy with 4 network interfaces that runs an Apache service which is accessed by an IP address managed by the cluster.
The following picture represents the network diagram:
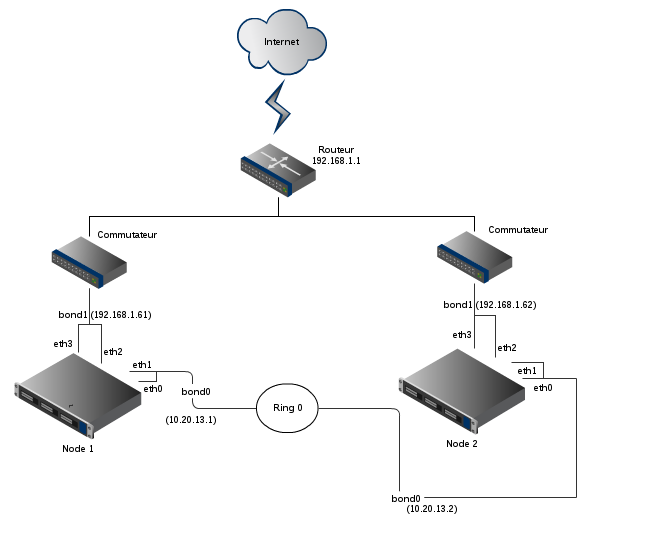
The eth0 and eth1 interfaces are part of a logical link aggregation and they help the cluster to check the status of the other nodes. They constitute a private network with the other nodes in the network 10.20.13.0/255.255.255.252. The interfaces eth2 and eth3 are part of another logical aggregation, they provide service at outside in the 192.168.1.0/24 network.
The logical aggregation (also called bonding) provides an additional redundancy. If the network adaptor eth0 burn out, the traffic still pass through eth1. It can be configured in active / passive mode or in load-balancing mode.
Here is the configuration of the interfaces on the vm-node1 machine in “/etc/network/interfaces/”:
auto bond0 iface bond0 inet static address 10.20.13.1 netmask 255.255.255.252 bond_mode active-backup bond_miimon 100 bond_downdelay 200 bond_updelay 200 slaves eth0 eth1 auto bond1 iface bond1 inet static address 192.168.1.61 netmask 255.255.255.0 gateway 192.168.1.1 bond_mode active-backup bond_miimon 100 bond_downdelay 200 bond_updelay 200 slaves eth2 eth3
And the configuration of the bonding in “/etc/modprobe.d/bonding”:
alias bond0 bonding alias bond1 bonding
The network configuration of the vm-node2 machine is symmetrical with bond0 in 10.20.13.2 and bond1 in 192.168.1.62. When the network configuration is dine, we can handle the cluster. First you need to install Corosync and Pacemaker on Debian, you will do as follow:
apt-get install corosyncpacemaker
Then configure Corosync. It manages the cluster infrastructure, which means the state of the nodes and their functioning in group. For this, we have to generate a key for authentication which will be shared by all nodes in the cluster. The corosync-keygen utility to generate this key from pseudo-random keystrokes which must then be secured and copied to other nodes.
# generation of the key from vm-node1 corosync-keygen mvauthkey/etc/corosync/authkey chownroot:root/etc/corosync/authkey chmod400/etc/corosync/authkey # copy of the key to vm-node2 scp/etc/corosync/authkeyroot@10.20.13.2:/etc/corosync/authkey
Corosync proposes the concept of connection rings to enable the communication between nodes. As part of the model, we defined two rings: ring0, the default communication ring that uses the private network and ring1, a backup ring that passes through the switches with the rest of the traffic. Corosync lets you define the rings in terms of IP / netmask rather than defining IP addresses. This is significant because the same configuration file can be deployed on all nodes without changing anything.
totem {
version:2
#How long before declaring a token lost(ms)
token:3000
#How many token retransmits before forming a new configuration
token_retransmits_before_loss_const:10
#How long to wait for joining messages in the membership protocol(ms)
join:60
#How long to wait for consensus to be achieved before starting a new round of membership configuration(ms) consensus:3600
#Turn off the virtual synchrony filter
vsftype:none
#Number of messages that may be sent by one processor on receipt of the token
max_messages:20
#Limit generated nodeids to 31-bits(positive signed integers)
clear_node_high_bit:yes
#Disable encryption
secauth:off
#How many threads to use for encryption/decryption
threads:0
#Optionally assign a fixed nodeid(integer)
#nodeid:1234
#This specifies the mode of redundant ring,which may be none,active,or passive.
rrp_mode:passive
interface {
ringnumber:0
bindnetaddr:10.20.13.0
mcastaddr:226.94.1.1
mcastport:5405
}
interface {
ringnumber:1
bindnetaddr:192.168.1.0
mcastaddr:226.94.1.1
mcastport:5407
}
}
amf {
mode:disabled
}
service {
#Load the Pacemaker Cluster Resource Manager
ver: 0
name: pacemaker
}
aisexec {
user: root
group: root
}
logging {
fileline:off
to_stderr:yes
to_logfile:no
to_syslog:yes
syslog_facility:daemon
debug:off
timestamp:on
logger_subsys {
subsys:AMF
debug:off
tags:enter|leave|trace1|trace2|trace3|trace4|trace6
}
}
At this point, the cluster infrastructure is in place but it does not manage any resource. It is the role of Pacemaker.
It has the following operational constraints:
- resources (Apache service and the cluster IP address) running on the server vm-node1 in the normal case.
- Apache service and the cluster IP address must run on the same server if our service is unreachable.
- If the Apache service crashes on the primary server, it switches to the secondary server.
- if the primary server is attached over the Internet gateway, it switches to the secondary server.
Pacemaker provides some utility in text mode to interact.
- CRM to manage all aspect configuration.
- crm_mon displays the state of the cluster.
First we define the global configuration. Quenched STONITH (Shoot The Other Node In The Head) and the quorum. STONITH is the ability to kill the other node if it no longer meets the infra cluster. And the quorum, it does not work on a cluster within 3 knots.
property stonith-enabled=false property no-quorum-policy=ignore
We can now define our first resource: cluster IP address attached to the active node.
primitive vip ocf:heartbeat:IPaddr2 params ip=192.168.1.60 cidr_netmask=24nic="bond1"op monitor interval="10s"
Then the Apache resource, the critical service we want to provide in this model:
primitive httpd ocf:heartbeat:apache params configfile="/etc/apache2/apache2.conf"statusurl="http://localhost/server-status"op start timeout="60s"op stop timeout="60s"op monitor timeout="20s"
The starting and stopping of Apache are now managed by the cluster. So, we have now to remove the automatic start of the service:
update-rc.d-fremoveapache2
You will notice that goes beyond the definition of an Apache resource. The Pacemaker STATUSURL attribute allows to use the Apache status page to determine a rocker. So do not forget to configure this URL in Apache:
<Location/server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from 127.0.0.1
</Location>
As we built the configuration step, crm_mon back perhaps there are some errors on certain resources because it was not operational. There is a failure counter that notifies us in case of warning. we can reset this timer for the resource http using the following command:
crm resource clean up httpd
At this stage we have a cluster address and an HTTP resource, but not necessarily on the same node. vip resource will switch if the node is dropped down. The httpd resource will switch if the node is dropped or the apache service rises (monitoring by URL / server-status).
Let’s go further and force both resources to run on the same node:
colocation httpd-with-vip inf : httpd vip
And we would like to have this also in the normal case, the resources run on vm-node1, our primary node:
location preferred-node vip 100 : vm-node1
Finally, we add a scale condition. If the node doesn’t reach the gateway over the Internet, we want to move resources to the other node For this we define a resource at the ping type that runs on all nodes (through the concept of cloned resource). Then a vacation rule is added to switch if the active node does not see the bridge.
primitive ping-gateway ocf:pacemaker:ping params host_list="192.168.1.1"multiplier="1000"op monitor interval="10s" clone cloned-ping-gateway ping-gateway location vip-needs-gateway vip rule-inf:not_defined pingd or pingd lte 0
This is our operational model. and we hope that we help you to do it.



{kind=link}