
Backup Files From Ubuntu Or Debian Server’s To Amazon s3
Every Organization need the data’s well protected than anything else, In IT field data’s are the only precious gem we can’t get back if we loose it in any case. So there will be more need to protect the data’s with high availability. If we have several VPS and we need to backup those data’s to Amazon S3 we can Use a Command line tool to copy the files from VPS server’s to Amazon s3 using copy command or using sync option. Instead of making copy we can take incremental backups in s3cmd command line too. Let we see how to setup s3 command line tool and backup our data’s to Amazon S3.
Note : Here My Bucket name is srvdata_backups
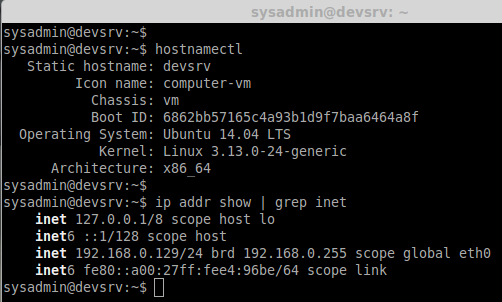
My Server Setup:
Hostname : devsrv.unixmen.com
IP Address : 192.168.0.129
hostnamectl
ip addr show | grep inet
Step By Step Installation
Step 1: Add the Key for S3 command line tool.file.
First we need to install the S3 tool package. For that we have to install the key.
sudo wget -O- -q http://s3tools.org/repo/deb-all/stable/s3tools.key | sudo apt-key add -

Step 2: Add the Repository:
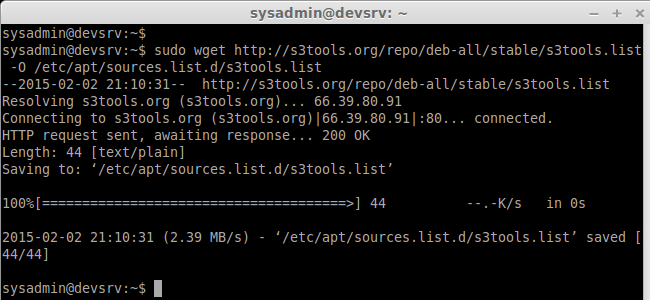
After adding the key let we add the repository to get the s3cmd.
sudo wget http://s3tools.org/repo/deb-all/stable/s3tools.list -O /etc/apt/sources.list.d/s3tools.list
Step 3: Install the s3cmd command line tool.
After adding the repository we have to Update the Repository cache and get Install the s3cmd Package.
sudo apt-get update && apt-get install s3cmd

Step 4: configure the s3 storage setting in Server:
After installing the package we need to configure the amazon s3 Bucket configuration as below.
s3cmd --configure
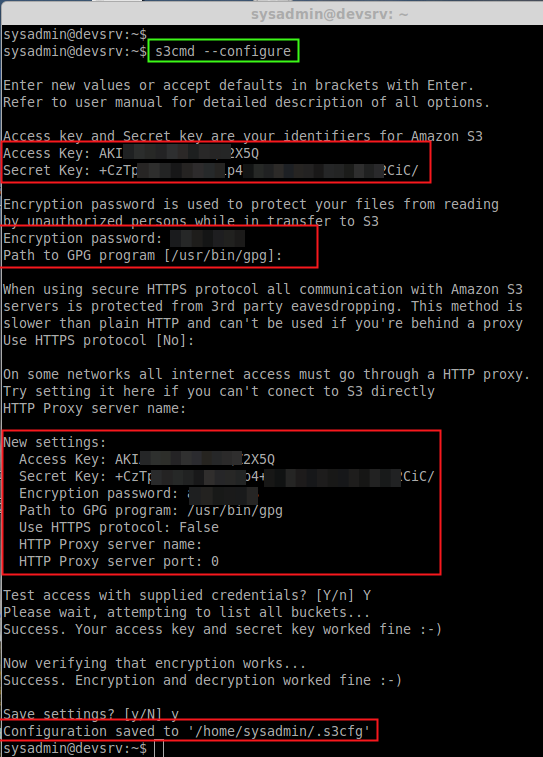
While run the configure option with s3cmd we need to provide the username and password.
* access secret
* access secret key
* Choose a encryption password & Confirm too
* choose if you have http or https
Step 5: Create S3 Bucket in Amazon from Command line:
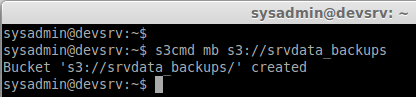
Here we can Create a Bucket to upload our files using s3cmd.
mb = Make Bucket.
s3cmd mb s3://srvdata_backups
If we need to list the Created Directory use command
s3cmd ls
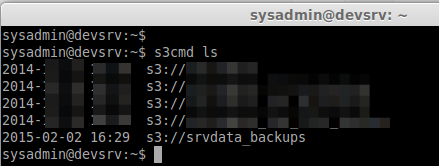
Step 6: Uploading files to S3 Storage.
Now we can upload a file to our above created Bucket.
s3cmd put test.tar.gz s3://srvdata_backups
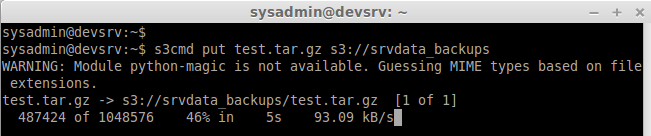
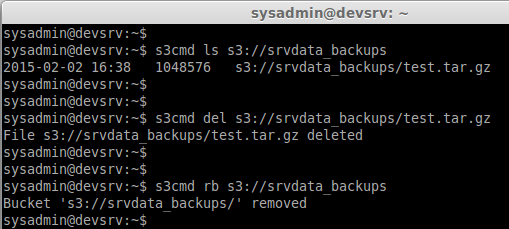
Step 7: List the file in create Bucket:
If we need to list the file which we have uploaded now Use command
s3cmd ls s3://srvdata_backups/
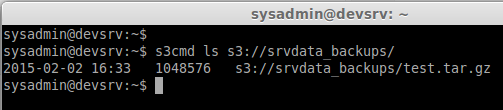
Step 8: Download from the S3 bucket.
To get the file from S3 Bucket use get command
s3cmd get s3://srvdata_backups/test.tar.gz
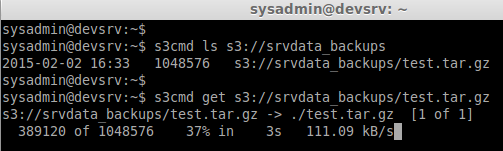
To delete the file in bucket use the below command.
s3cmd del s3://srvdata_backups/test.tar.gz

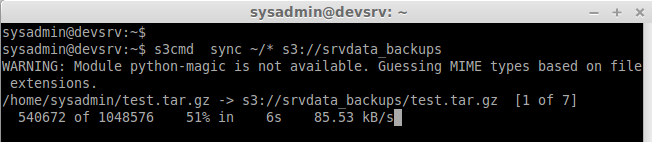
Step 9: Sync file’s instead of Copying:
s3cmd sync ~/* s3://srvdata_backups
Step 10: To remove a Amazon S3 Bucket:
rb = Remove Bucket
s3cmd rb s3://srvdata_backups
Instead of Copying files from Server to S3 we can use sync command, This will provide us incremental backup. Thus we can copy a file from ubuntu or Debian Server’s to S3 bucket. Hope you have found a way to store your files in Amazon S3 Storage.



{kind=link}